



We propose a new approach to human clothing modeling based on point clouds. Within this approach, we learn a deep model that can predict point clouds of various outfits, for various human poses, and for various human body shapes. Notably, outfits of various types and topologies can be handled by the same model. Using the learned model, we can infer the geometry of new outfits from as little as a single image, and perform outfit retargeting to new bodies in new poses. We complement our geometric model with appearance modeling that uses the point cloud geometry as a geometric scaffolding and employs neural point-based graphics to capture outfit appearance from videos and to re-render the captured outfits. We validate both geometric modeling and appearance modeling aspects of the proposed approach against recently proposed methods and establish the viability of point-based clothing modeling.
Our method could be viewed as 3 parts:
- Draping network training and Outfit code space learning
- Single-image outfit geometry reconstruction
- Neural point-based appearance modeling
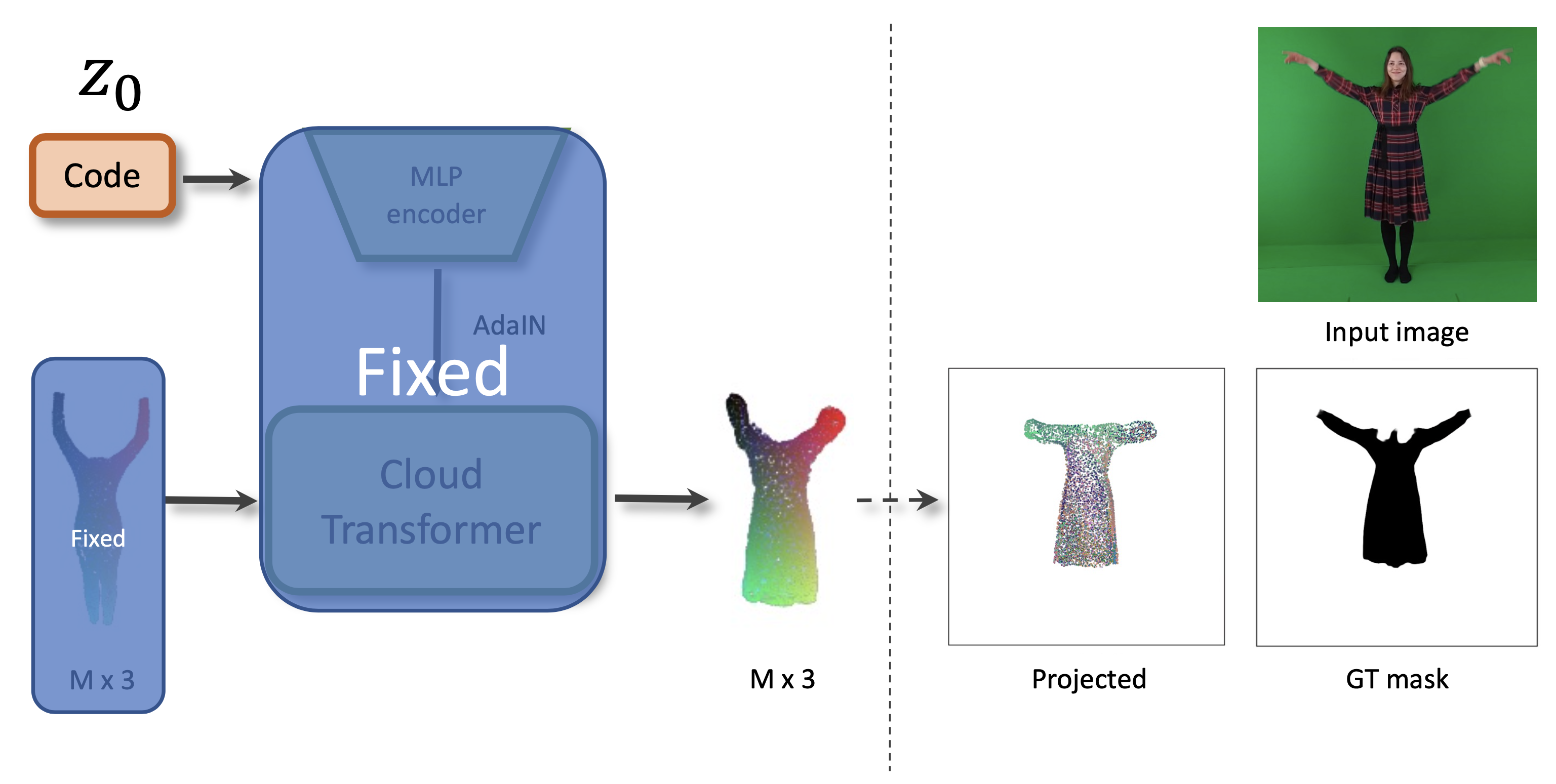
The draping network takes the latent code of a clothing outfit, the subset of vertices of an SMPL body mesh, and predicts the point cloud of the clothing outfit adapted to the body shape and the body pose. We use the recently proposed Cloud Transformer architecture to perform the mapping.
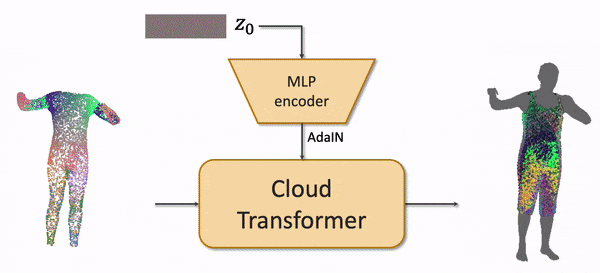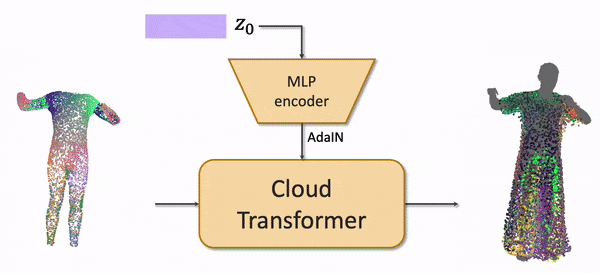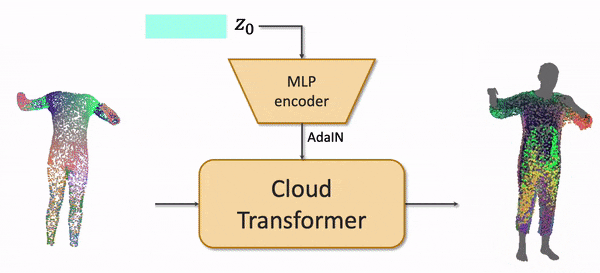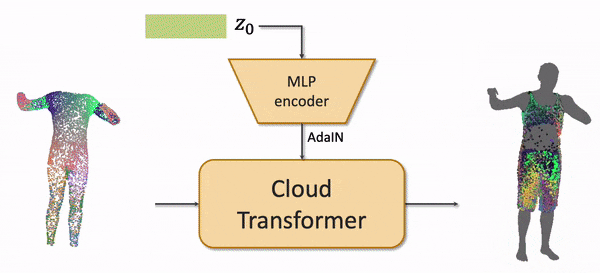
We train the model by fitting it to a Cloth3D synthetic dataset of physically simulated clothing using Generative Latent Optimization approach. After fitting, the outfits in the training dataset all get latent codes.
Given an input image, its segmentation, and its SMPL mesh fit, we can find the latent code of the outfit. The code is obtained by optimizing the mismatch between the segmentation and the projection of the point cloud. The draping network remains frozen during this process, only the outfit code vector is being changed (we are "searching" in the latent space).
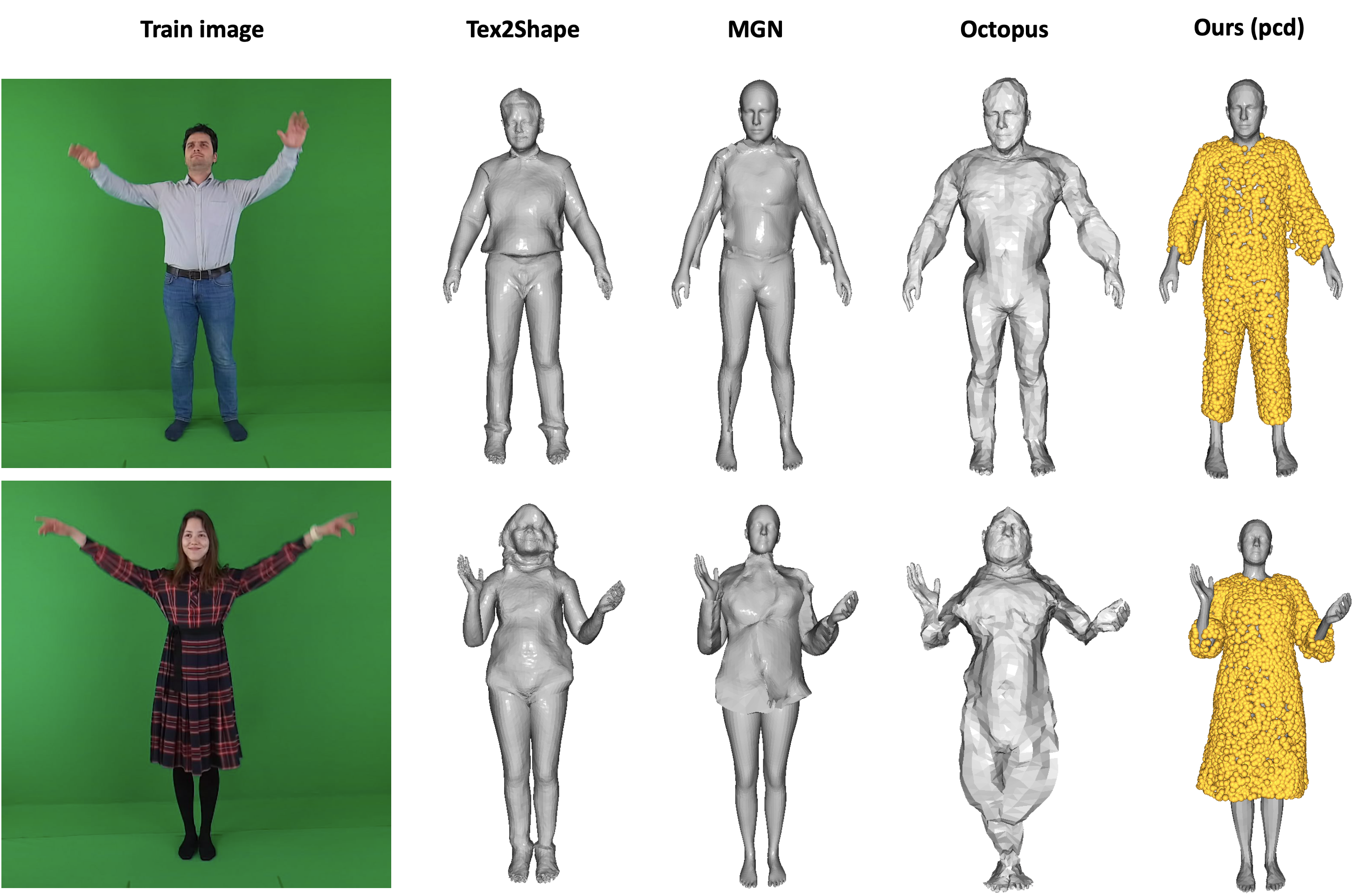

Left: Comparison on AzurePeople dataset. Right: Reconstruction from in-the-wild internet images.
We expand our geometric model further to include appearance modeling. We use the neural point-based graphics approach. In more detail, we assign each outfput point a neural appearance descriptor and introduce a rendering network. We then fit the parameters of this network as well as the appearance descriptors to a video of a person wearing a certain outfit. The appearance fitting is performed after we fit the clothing geometry.
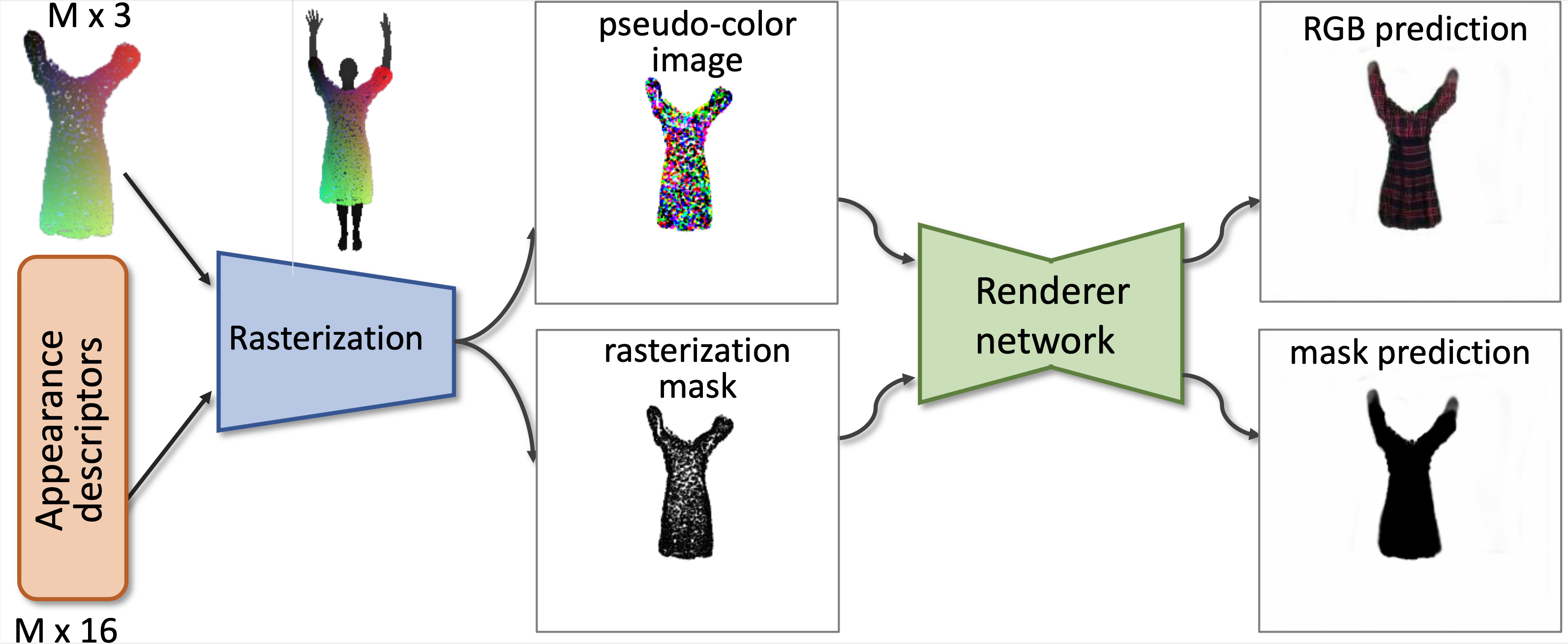


Left: AzurePeople dataset. Right: PeopleSnapshot dataset.
Given an input video with SMPL mesh calculated for each frame, our model is able to retarget and repose the clothing learned from any other video. Our approach could be used for virtual try-on on images as well (more simple case than a video).



